
(责任编辑:娱乐)
 Canva 新闻封面与信息图专业模板:新闻编辑的高效设计利器
Canva 新闻封面与信息图专业模板:新闻编辑的高效设计利器 Copyscape 新闻原创性检测与抄袭预防
Copyscape 新闻原创性检测与抄袭预防 Final Cut Pro 多机位编辑:新闻制作中的智能利器
Final Cut Pro 多机位编辑:新闻制作中的智能利器 Cision 新闻发布监测与媒体数据库应用:智能化公关必备工具
Cision 新闻发布监测与媒体数据库应用:智能化公关必备工具 三星Galaxy S25 Ultra渲染图曝光:设计革新与性能突破全面解析
三星Galaxy S25 Ultra渲染图曝光:设计革新与性能突破全面解析 蔚来汽车近日宣布,其全国换电站数量已正式突破2500座大关,标志着换电网络布局进入全新阶段。与此同时,蔚来与中石化的战略合作持续深化,双方计划在2025年内新增超过500座共建换电站,覆盖高速公路服务
...[详细]
蔚来汽车近日宣布,其全国换电站数量已正式突破2500座大关,标志着换电网络布局进入全新阶段。与此同时,蔚来与中石化的战略合作持续深化,双方计划在2025年内新增超过500座共建换电站,覆盖高速公路服务
...[详细]特斯拉4680电池与比亚迪CTB底盘一体化技术深度对比:智能分析工具助你洞悉未来
 在新能源汽车的激烈竞争中,特斯拉4680电池与比亚迪CTBCell to Body)底盘一体化技术代表了两种截然不同的技术路线。为了帮助工程师、投资者和科技爱好者快速掌握两者的核心差异,我们推荐使用一
...[详细]
在新能源汽车的激烈竞争中,特斯拉4680电池与比亚迪CTBCell to Body)底盘一体化技术代表了两种截然不同的技术路线。为了帮助工程师、投资者和科技爱好者快速掌握两者的核心差异,我们推荐使用一
...[详细]Midjourney 风格一致性控制:参数与种子锁定技术深度解析
 在人工智能图像生成领域,Midjourney 以其卓越的艺术表现力与风格多样性著称。然而,对于需要批量产出品牌视觉、角色设计或系列插画的专业用户而言,如何确保每次生成的图像在风格、构图和意境上保持高度
...[详细]
在人工智能图像生成领域,Midjourney 以其卓越的艺术表现力与风格多样性著称。然而,对于需要批量产出品牌视觉、角色设计或系列插画的专业用户而言,如何确保每次生成的图像在风格、构图和意境上保持高度
...[详细]Snopes事实核查API集成:提升编辑工作流可信度的智能工具
 在信息爆炸的时代,事实核查已成为新闻编辑室的核心环节。Snopes官方网站提供了强大的事实核查API,允许编辑团队无缝将其集成到现有工作流中,从而自动验证内容真实性。本文将深入介绍该工具的功能、优势、
...[详细]
在信息爆炸的时代,事实核查已成为新闻编辑室的核心环节。Snopes官方网站提供了强大的事实核查API,允许编辑团队无缝将其集成到现有工作流中,从而自动验证内容真实性。本文将深入介绍该工具的功能、优势、
...[详细]Hemingway Editor 新闻文稿可读性优化:智能工具让新闻写作更高效
 作为新闻编辑专家,我每天都在处理大量新闻稿件。最近,国产大飞机C919首次执飞新加坡国际航线成为热点新闻,但初稿中句子冗长、被动语态多,导致读者理解困难。这正是 Hemingway Editor 大显
...[详细]
作为新闻编辑专家,我每天都在处理大量新闻稿件。最近,国产大飞机C919首次执飞新加坡国际航线成为热点新闻,但初稿中句子冗长、被动语态多,导致读者理解困难。这正是 Hemingway Editor 大显
...[详细]Elasticsearch News Indexing Performance Tuning 智能调优工具详解
 在当今实时新闻与内容聚合场景中,Elasticsearch 作为核心搜索引擎,其索引性能直接决定了新闻系统的响应速度与吞吐量。本文介绍一款由 Elastic 官方推出的智能调优工具——Elastics
...[详细]
在当今实时新闻与内容聚合场景中,Elasticsearch 作为核心搜索引擎,其索引性能直接决定了新闻系统的响应速度与吞吐量。本文介绍一款由 Elastic 官方推出的智能调优工具——Elastics
...[详细]NewsWhip Spike:预测病毒式新闻内容的智能分析工具
 在信息爆炸的媒体环境中,提前预测哪些内容会引发病毒式传播,是新闻编辑室和内容团队的核心竞争力。NewsWhip Spike 正是为这一需求而生的预测分析平台,它通过实时追踪社交媒体的互动数据,帮助用户
...[详细]
在信息爆炸的媒体环境中,提前预测哪些内容会引发病毒式传播,是新闻编辑室和内容团队的核心竞争力。NewsWhip Spike 正是为这一需求而生的预测分析平台,它通过实时追踪社交媒体的互动数据,帮助用户
...[详细] 近日,抖音电商宣布其年度商品交易总额GMV)正式突破2万亿元大关,这一数据标志着抖音电商在短短几年内迅速崛起,成为国内电商市场的重要力量。据行业分析,抖音电商凭借其独特的短视频和直播带货模式,成功吸引
...[详细]
近日,抖音电商宣布其年度商品交易总额GMV)正式突破2万亿元大关,这一数据标志着抖音电商在短短几年内迅速崛起,成为国内电商市场的重要力量。据行业分析,抖音电商凭借其独特的短视频和直播带货模式,成功吸引
...[详细]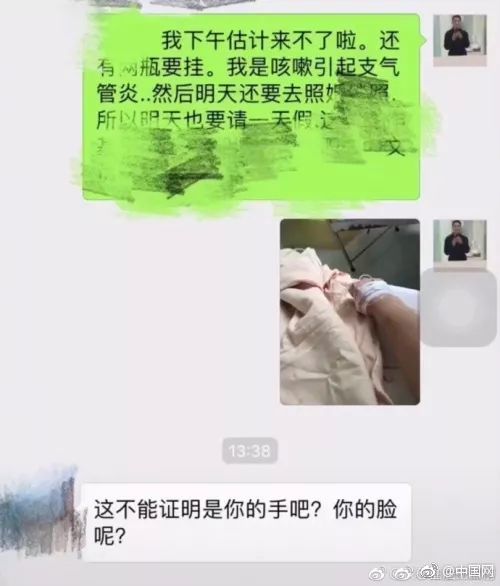 近日,抖音官方宣布推出一系列针对AI换脸诈骗的全新打击措施,旨在保护用户免受深度伪造技术带来的欺诈风险。作为国内领先的短视频平台,抖音此次升级了基于人工智能的实时检测系统,能够精准识别视频内容中的换脸
...[详细]
近日,抖音官方宣布推出一系列针对AI换脸诈骗的全新打击措施,旨在保护用户免受深度伪造技术带来的欺诈风险。作为国内领先的短视频平台,抖音此次升级了基于人工智能的实时检测系统,能够精准识别视频内容中的换脸
...[详细] 在当今数字化转型浪潮中,企业知识管理成为提升竞争力的关键。ChatGPT 推出的自定义 GPTs 功能,允许用户通过自然语言指令创建专属 AI 助手,无需编程即可构建企业级知识库系统。本教程将详细解析
...[详细]
在当今数字化转型浪潮中,企业知识管理成为提升竞争力的关键。ChatGPT 推出的自定义 GPTs 功能,允许用户通过自然语言指令创建专属 AI 助手,无需编程即可构建企业级知识库系统。本教程将详细解析
...[详细]
